Modern C++# Grammar# std::ranges# std::ranges 库的核心思想是让算法直接操作容器(而非迭代器对),并支持管道式(pipeline)链式调用。
对比以前的迭代器使用方式:
1
2
3
4
5
6
7
// 找到指定元素
std :: sort ( v . begin (), v . end ());
auto it = std :: find ( v . begin (), v . end (), 4 );
// std::ranges
std :: ranges :: sort ( v );
auto it = std :: ranges :: find ( v , 4 );
以下是一些std::ranges的常用方式:
转换:
std::transform 1
2
3
4
5
6
7
8
9
10
11
12
struct Player {
std :: string name ;
int score ;
};
std :: vector < Player > players = {{ "Alice" , 90 }, { "Bob" , 75 }, { "Carol" , 88 }};
// 提取所有玩家名字
auto names = players | std :: views :: transform ( & Player :: name );
// → {"Alice", "Bob", "Carol"}(惰性视图,不拷贝)
// 提取分数并乘以 1.1 加权
auto weighted = players
| std :: views :: transform ([]( const Player & p ) { return p . score * 1.1 ; });
// → {99.0, 82.5, 96.8}
过滤:
std::filter 1
2
3
4
5
6
7
8
9
// 管道组合:筛选后提取名字
auto highNames = players
| std :: views :: filter ([]( const Player & p ) { return p . score > 80 ; })
| std :: views :: transform ( & Player :: name );
// → {"Alice", "Carol"}
// 从整数序列中提取偶数
auto evens = std :: views :: iota ( 1 , 20 )
| std :: views :: filter ([]( int n ) { return n % 2 == 0 ; });
// → {2, 4, 6, 8, 10, 12, 14, 16, 18}
排序:
std::sort 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// 按 score 升序排序(第三个参数是投影 projection)
std :: ranges :: sort ( players , {}, & Player :: score );
// 降序
std :: ranges :: sort ( players , std :: greater {}, & Player :: score );
// 按名字字典序
std :: ranges :: sort ( players , {}, & Player :: name );
// 稳定排序
std :: ranges :: stable_sort ( players , std :: less {}, & Player :: score );
// 部分排序:只排出前 3 名
std :: ranges :: partial_sort ( players , players . begin () + 3 , std :: greater {}, & Player :: score );
// nth_element:把第 n 大的放到正确位置,左边都比它小,右边都比它大
std :: ranges :: nth_element ( players , players . begin () + 2 , {}, & Player :: score );
查找:
std::find 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 查找第一个分数大于 85 的
auto it = std :: ranges :: find_if ( players , []( const Player & p ) {
return p . score > 85 ;
});
// 用投影简化:查找名字为 "Bob" 的
auto bob = std :: ranges :: find ( players , "Bob" , & Player :: name );
// 检查是否存在
bool hasBob = std :: ranges :: find ( players , "Bob" , & Player :: name ) != players . end ();
// any_of / all_of / none_of
bool anyHigh = std :: ranges :: any_of ( players , []( const Player & p ) { return p . score > 95 ; }); // 存在一个true就返回 true
bool allPass = std :: ranges :: all_of ( players , []( const Player & p ) { return p . score >= 60 ; }); // 所有的都为true才返回 true
// 二分查找(容器需已排序)
std :: ranges :: sort ( players , {}, & Player :: score );
bool found = std :: ranges :: binary_search ( players , 90 , {}, & Player :: score );
// lower_bound 指向 第一个 >= value 的元素 / upper_bound 指向 第一个 > value 的元素
auto lb = std :: ranges :: lower_bound ( players , 80 , {}, & Player :: score );
遍历:
for_each
1
2
3
// 将数组内所有元素置0
std :: vector < int > matrix { 0 , 1 , 0 , 2 , 3 };
std :: ranges :: for_each ( matrix , []( auto & value ) { value = 0 ; });
iota
1
2
3
4
5
#include <numeric>
std :: vector < int > v ( 5 );
std :: iota ( v . begin (), v . end (), 10 );
// 输出 10, 11, 12, 13, 14
std :: ranges :: iota ( v , 10 ); // 等效
判断是否存在满足条件的元素:
contains 1
2
3
// 检查是否包含0元素
std :: vector < int > matrix { 0 , 1 , 0 , 2 , 3 };
bool hasZero = std :: ranges :: contains ( matrix , 0 );
any_of 1
2
3
4
5
// 检查是否包含0元素
std :: vector < int > matrix { 0 , 1 , 0 , 2 , 3 };
bool hasZero = std :: ranges :: any_of ( matrix , []( auto & value ) -> bool {
return value == 0
});
其他:
take、drop:截取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
struct Employee {
std :: string name ;
int salary ;
int departmentId ;
};
std :: vector < Employee > employees = {
{ "Alice" , 8000 , 1 }, { "Bob" , 12000 , 2 }, { "Carol" , 9500 , 1 },
{ "Dave" , 15000 , 3 }, { "Eve" , 7000 , 2 }
};
auto firstThree = employees | std :: views :: take ( 3 ); // 截取三个
// -> Alice, Bob, Carol
auto skipTwo = employees | std :: views :: drop ( 2 ); // 丢弃两个
// -> Carol, Dave, Eve
提取容器Key、Value
1
2
3
4
std :: map < std :: string , int > scoreMap = {{ "Alice" , 90 }, { "Bob" , 85 }};
auto names = scoreMap | std :: views :: keys ; // -> "Alice", "Bob"
auto scores = scoreMap | std :: views :: values ; // -> 90, 85
反转
1
2
3
4
auto reversed = employees
| std :: views :: transform ( & Employee :: name )
| std :: views :: reverse ;
// -> "Eve", "Dave", "Carol", "Bob", "Alice"
std::filesystem# 容器小tips# 大小根堆# std::priority_queue为标准库自带的大根堆,默认为:std::priority_queue<T, std::vector<T>, std::less<>>,自定义排序版的堆为:
1
2
3
4
auto cmp = []( const T left , const T right ) {
return left > right ; // 小根堆,与排序相反,比较返回true时默认left节点下沉
};
std :: priority_queue < T , std :: vector < T > , decltype ( cmp ) > heap ;
std::priority_queue本身为对<algorithm>中make_heap、push_heap、pop_heap、is_heap等方法的封装,所以第二个模板参数需要提供支持随机访问 的容器:
1
2
3
4
5
6
7
8
9
10
vector < int > vec = { 3 , 1 , 5 , 2 };
// 构建大根堆
make_heap ( vec . begin (), vec . end ());
// 插入新元素
vec . push_back ( 6 );
push_heap ( vec . begin (), vec . end ());
// 弹出堆顶
pop_heap ( vec . begin (), vec . end ());
vec . pop_back ();
// ...
基于vector手动实现堆排序:
std::string# 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
#include <cstring>
#include <iostream>
#include <algorithm>
#include <stdexcept>
class MyString {
public :
using iterator = char * ;
using const_iterator = const char * ;
static const size_t npos = static_cast < size_t > ( - 1 );
MyString ()
: m_data ( new char [ 1 ])
, m_size ( 0 )
, m_capacity ( 0 )
{
m_data [ 0 ] = '\0' ;
}
MyString ( const char * str )
{
if ( str == nullptr )
{
m_size = 0 ;
m_capacity = 0 ;
m_data = new char [ 1 ];
m_data [ 0 ] = '\0' ;
}
else
{
m_size = std :: strlen ( str );
m_capacity = m_size ;
m_data = new char [ m_capacity + 1 ];
std :: memcpy ( m_data , str , m_size + 1 );
}
}
MyString ( size_t count , char ch )
: m_data ( new char [ count + 1 ])
, m_size ( count )
, m_capacity ( count )
{
std :: memset ( m_data , ch , count );
m_data [ m_size ] = '\0' ;
}
~ MyString ()
{
delete [] m_data ;
}
// 拷贝构造
MyString ( const MyString & other )
: m_data ( new char [ other . m_size + 1 ])
, m_size ( other . m_size )
, m_capacity ( other . m_size )
{
std :: memcpy ( m_data , other . m_data , m_size + 1 );
}
// 移动构造
MyString ( MyString && other ) noexcept
: m_data ( other . m_data )
, m_size ( other . m_size )
, m_capacity ( other . m_capacity )
{
other . m_data = new char [ 1 ];
other . m_data [ 0 ] = '\0' ;
other . m_size = 0 ;
other . m_capacity = 0 ;
}
MyString & operator = ( MyString other ) noexcept
{
swap ( other );
return * this ;
}
// 容量相关
size_t size () const noexcept { return m_size ; }
size_t length () const noexcept { return m_size ; }
size_t capacity () const noexcept { return m_capacity ; }
bool empty () const noexcept { return m_size == 0 ; }
// c_str()
const char * c_str () const noexcept { return m_data ; }
const char * data () const noexcept { return m_data ; }
// 预分配容量
void reserve ( size_t newCap )
{
if ( newCap <= m_capacity ) return ;
char * newData = new char [ newCap + 1 ];
std :: memcpy ( newData , m_data , m_size + 1 );
delete [] m_data ;
m_data = newData ;
m_capacity = newCap ;
}
void clear () noexcept
{
m_size = 0 ;
m_data [ 0 ] = '\0' ;
}
// operator[]
char & operator []( size_t pos ) { return m_data [ pos ]; }
const char & operator []( size_t pos ) const { return m_data [ pos ]; }
// at() 做越界检查,抛 std::out_of_range
char & at ( size_t pos )
{
if ( pos >= m_size ) throw std :: out_of_range ( "MyString::at" );
return m_data [ pos ];
}
const char & at ( size_t pos ) const
{
if ( pos >= m_size ) throw std :: out_of_range ( "MyString::at" );
return m_data [ pos ];
}
char & front () { return m_data [ 0 ]; }
const char & front () const { return m_data [ 0 ]; }
char & back () { return m_data [ m_size - 1 ]; }
const char & back () const { return m_data [ m_size - 1 ]; }
// 修改
MyString & operator += ( const MyString & rhs )
{
append ( rhs . m_data , rhs . m_size );
return * this ;
}
MyString & operator += ( const char * str )
{
append ( str , std :: strlen ( str ));
return * this ;
}
MyString & operator += ( char ch )
{
push_back ( ch );
return * this ;
}
// 2 倍扩容
void push_back ( char ch )
{
if ( m_size == m_capacity ) {
reserve ( m_capacity == 0 ? 1 : m_capacity * 2 );
}
m_data [ m_size ++ ] = ch ;
m_data [ m_size ] = '\0' ;
}
void pop_back ()
{
if ( m_size > 0 ) {
m_data [ -- m_size ] = '\0' ;
}
}
size_t find ( const char * target , size_t pos = 0 ) const
{
if ( pos > m_size ) return npos ;
const char * found = std :: strstr ( m_data + pos , target );
return found ? static_cast < size_t > ( found - m_data ) : npos ;
}
size_t find ( char ch , size_t pos = 0 ) const
{
for ( size_t i = pos ; i < m_size ; ++ i ) {
if ( m_data [ i ] == ch ) return i ;
}
return npos ;
}
size_t find ( const MyString & str , size_t pos = 0 ) const
{
return find ( str . m_data , pos );
}
MyString substr ( size_t pos = 0 , size_t count = npos ) const
{
if ( pos > m_size ) throw std :: out_of_range ( "MyString::substr" );
size_t len = std :: min ( count , m_size - pos );
MyString result ;
result . reserve ( len );
result . m_size = len ;
std :: memcpy ( result . m_data , m_data + pos , len );
result . m_data [ len ] = '\0' ;
return result ;
}
void swap ( MyString & other ) noexcept
{
std :: swap ( m_data , other . m_data );
std :: swap ( m_size , other . m_size );
std :: swap ( m_capacity , other . m_capacity );
}
int compare ( const MyString & other ) const noexcept
{
return std :: strcmp ( m_data , other . m_data );
}
iterator begin () noexcept { return m_data ; }
iterator end () noexcept { return m_data + m_size ; }
const_iterator begin () const noexcept { return m_data ; }
const_iterator end () const noexcept { return m_data + m_size ; }
const_iterator cbegin () const noexcept { return m_data ; }
const_iterator cend () const noexcept { return m_data + m_size ; }
// operator+
friend MyString operator + ( const MyString & lhs , const MyString & rhs )
{
MyString result ;
result . reserve ( lhs . m_size + rhs . m_size );
result . append ( lhs . m_data , lhs . m_size );
result . append ( rhs . m_data , rhs . m_size );
return result ;
}
// 比较运算符:先比 size 做短路优化
friend bool operator == ( const MyString & a , const MyString & b ) noexcept
{
return a . m_size == b . m_size && std :: memcmp ( a . m_data , b . m_data , a . m_size ) == 0 ;
}
friend bool operator != ( const MyString & a , const MyString & b ) noexcept { return ! ( a == b ); }
friend bool operator < ( const MyString & a , const MyString & b ) noexcept { return a . compare ( b ) < 0 ; }
friend bool operator <= ( const MyString & a , const MyString & b ) noexcept { return a . compare ( b ) <= 0 ; }
friend bool operator > ( const MyString & a , const MyString & b ) noexcept { return a . compare ( b ) > 0 ; }
friend bool operator >= ( const MyString & a , const MyString & b ) noexcept { return a . compare ( b ) >= 0 ; }
private :
// 追加 len 个字符到末尾
void append ( const char * str , size_t len )
{
if ( m_size + len > m_capacity ) {
reserve ( std :: max ( m_capacity * 2 , m_size + len ));
}
std :: memcpy ( m_data + m_size , str , len );
m_size += len ;
m_data [ m_size ] = '\0' ;
}
char * m_data ;
size_t m_size ;
size_t m_capacity ;
};
一些小细节# 比较运算符
关于比较运算符的重载,C++20提供了更高效的 <=> 运算符重载,可以更高效的重载比较运算符,所以上面的代码可以修改为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#include <compare>
// ...
friend bool operator == ( const MyString & a , const MyString & b ) noexcept
{
return a . m_size == b . m_size && std :: memcmp ( a . m_data , b . m_data , a . m_size ) == 0 ;
}
friend std :: strong_ordering operator <=> ( const MyString & a , const MyString & b ) noexcept
{
int result = std :: strcmp ( a . m_data , b . m_data );
if ( result < 0 ) return std :: strong_ordering :: less ;
if ( result > 0 ) return std :: strong_ordering :: greater ;
return std :: strong_ordering :: equal ;
}
对于比较结果,C++20提供了三种不同强度的类型:
1
2
3
std :: strong_ordering // :强排序,equal时两个值完全相同,可以相互替换(枚举、字符串、Point值类型等)
std :: weak_ordering // :弱排序,equal时两个值不一定完全相同,仅仅在判断时表示相同
std :: partial_ordering // :部分排序,相比于weak_ordering,还多了一个 unordered 状态,表示两个值无法比较大小
友元
C++ 中有三种友元形式:友元函数、友元类、友元成员函数:
友元函数
类内定义的友元函数:
1
2
3
4
5
6
7
8
9
10
11
class Object {
public :
Object ( size_t size ) : m_size ( size ) {}
// 在类体内部直接定义
friend bool operator == ( const Object & a , const Object & b ) noexcept
{
return a . m_size == b . m_size ;
}
private :
size_t m_size ;
};
这种定义方式会使得函数在全局命名空间不可见,只有当参数中包含Object类时,才会在Object的命名空间中查找该函数。对于Object(2) == 2 和 2 == Object(2),如果没有friend,后者会编译失败(在C++20之前)。
C++20之后引入了新的 == 运算符规则,允许编译器翻转运算符两边的内容)。
普通友元函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
class Object {
public :
Object ( size_t size ) : m_size ( size ) {}
friend bool operator == ( const Object & a , const Object & b ) noexcept ; // 声明
private :
size_t m_size ;
};
// 在类外部定义
friend bool operator == ( const Object & a , const Object & b ) noexcept
{
return a . m_size == b . m_size ;
}
适用于同时需要访问两个类的私有成员的场景。
友元类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Object {
public :
Object ( size_t size ) : m_size ( size ) {}
friend class OtherClass ;
private :
size_t m_size ;
};
class OtherClass {
public :
void print ( const Object & obj ) {
std :: cout << obj . m_size << std :: endl ; // 可以访问对方的私有成员,且单向访问
}
};
友元成员函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class B ; // 前向声明
class A {
public :
void inspect ( const B & b ); // 需要访问 B 的私有成员
};
class B {
friend void A :: inspect ( const B & b ); // 只授权 A 的这一个函数
private :
int m_secret = 42 ;
};
void A :: inspect ( const B & b ) {
std :: cout << b . m_secret ; // 可以访问对方的私有成员,且单向访问
}
std::vector# 堆、栈# std::map# 线程池# 无锁队列# Algorithm Template# 快速排序# 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// 快速排序
int _Partition ( std :: vector < int >& arr , int first , int last )
{
if ( first == last ) return first ;
int posVal = arr [ last ];
int i = first ;
for ( int j = first ; j < last ; j ++ )
{
if ( arr [ j ] < posVal )
std :: swap ( arr [ i ++ ], arr [ j ]);
}
std :: swap ( arr [ i ], arr [ last ]);
return i ;
}
void QuickSort ( std :: vector < int >& arr , int first , int last )
{
if ( first >= last ) return ;
int pos = _Partition ( arr , first , last );
QuickSort ( arr , first , pos - 1 );
QuickSort ( arr , pos + 1 , last );
}
时间复杂度:
对于理想待排序数组,即每次都能正好平均分原始数组时,树的递归深度(即“循环次数”)为:将数组长度N除以2直到长度为1或0的次数,即:N/2^x = 1,x = log2N。对于每一层树的处理,所有节点长度总是N,所以最终复杂度为:O(NlogN)。
对于最坏情况,即每次拆分数组都只能将原始数组分成0和n - 1的两个子数组,此时循环次数会退化回N,时间复杂度也来到最差情况:O(N^2)
对于std::sort,内部在选基准点时会选取前、中、后三个基准点,并取居中的数作为基准以避免极端情况,当递归次数过多时也会退化为“堆排序”。
快速排序的优势在于:每次处理子数组都是顺序处理,CPU友好,并且空间复杂度为递归深度O(logN),且没有资源拷贝开销。
Partition
上面的快排的Partition实现采用了快慢指针法 ,代码实现精简,但是可以注意到,对于近乎有序的数组,比如:
1
std :: vector < int > arr { 1 , 2 , 3 , 4 , 5 , 6 , 7 };
在初次排序时,需要swap七次才能将数字1放到他该放到的位置,这对于讲究速率的排序算法来说很致命,所以,我们可以通过双指针法 来避免上述问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
int _Partition2 ( std :: vector < int >& arr , int first , int last )
{
int pivot = arr [ last ];
int left = first ;
int right = last - 1 ;
while ( true )
{
while ( left <= right && arr [ left ] < pivot ) {
left ++ ;
}
while ( left <= right && arr [ right ] >= pivot ) {
right -- ;
}
if ( left >= right ) {
break ;
}
std :: swap ( arr [ left ], arr [ right ]);
left ++ ;
right -- ;
}
std :: swap ( arr [ left ], arr [ last ]);
return left ;
}
这种算法可以尽量避免不必要的交换,一定程度上提高排序的速度,毕竟Partition的目的只是分区。
如果要支持迭代器类型,可以将参数做如下修改:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
template < typename RandomIt , typename Compare = std :: less < typename std :: iterator_traits < RandomIt >:: value_type >>
RandomIt partition ( RandomIt first , RandomIt last , Compare comp = Compare {}) {
if ( first == last ) return first ;
auto pivot_it = std :: prev ( last );
auto & pivot_val = * pivot_it ;
auto store = first ;
for ( auto it = first ; it != pivot_it ; ++ it ) {
if ( comp ( * it , pivot_val )) {
std :: swap ( * it , * store );
++ store ;
}
}
std :: swap ( * store , * pivot_it );
return store ;
}
template < typename RandomIt , typename Compare = std :: less < typename std :: iterator_traits < RandomIt >:: value_type >>
void quick_sort ( RandomIt first , RandomIt last , Compare comp = Compare {}) {
if ( std :: distance ( first , last ) <= 1 ) return ;
auto pivot_pos = :: partition ( first , last , comp );
quick_sort ( first , pivot_pos , comp );
quick_sort ( std :: next ( pivot_pos ), last , comp );
}
这里的RandomIt可以换成C++20的std::random_access_iterator,以限制迭代器为随机访问迭代器,否则当传入的迭代器类型为双向迭代器时,std::distance复杂度会退化成O(n),通过while (++it)来前进计算距离。
同时对于一长串的迭代器类型萃取,c++14提供了透明比较器 std::less<>,可以在进行比较时根据传入的参数来生成相应的实例化代码,区别在于前者仅支持相同类型的 ‘<’ 比较。
归并排序# 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
void _MergeRecursive ( std :: vector < int >& arr , std :: vector < int >& temp , int first , int mid , int last )
{
int tempIndex = first ;
int i = first , j = mid + 1 ;
while ( i <= mid && j <= last )
{
if ( arr [ i ] <= arr [ j ])
temp [ tempIndex ++ ] = arr [ i ++ ];
else
temp [ tempIndex ++ ] = arr [ j ++ ];
}
while ( i <= mid ) temp [ tempIndex ++ ] = arr [ i ++ ];
while ( j <= last ) temp [ tempIndex ++ ] = arr [ j ++ ];
for ( int k = first ; k <= last ; k ++ )
arr [ k ] = temp [ k ];
}
void MergeSortImpl ( std :: vector < int >& arr , std :: vector < int >& temp , int first , int last )
{
if ( first >= last ) return ;
int mid = first + ( last - first ) / 2 ;
MergeSortImpl ( arr , temp , first , mid );
MergeSortImpl ( arr , temp , mid + 1 , last );
_MergeRecursive ( arr , temp , first , mid , last );
}
void MergeSort ( std :: vector < int >& arr , int first , int last )
{
std :: vector < int > temp ( arr ); // 复用数组
MergeSortImpl ( arr , temp , first , last );
}
并查集# 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
class UnionFind {
std :: vector < int > parent , rank ;
int components ; // 连通分量数
public :
explicit UnionFind ( int n ) : parent ( n ), rank ( n , 0 ), components ( n ) {
std :: iota ( parent . begin (), parent . end (), 0 ); // parent[i] = i
}
int find ( int x ) {
while ( parent [ x ] != x ) {
parent [ x ] = parent [ parent [ x ]]; // 路径压缩(隔代压缩)
x = parent [ x ];
}
return x ;
}
bool unite ( int x , int y ) {
int rx = find ( x ), ry = find ( y );
if ( rx == ry ) return false ; // 已在同一集合
// 按秩合并:矮树挂到高树下
if ( rank [ rx ] < rank [ ry ]) std :: swap ( rx , ry );
parent [ ry ] = rx ;
if ( rank [ rx ] == rank [ ry ]) ++ rank [ rx ];
-- components ;
return true ;
}
bool connected ( int x , int y ) { return find ( x ) == find ( y ); }
int count () const { return components ; }
};
如果不做优化,最坏的情况下,整个并查集将退化回链表(即每次unite都顺序链接),查询联合的复杂度都是O(n)
按秩合并后,树的高度将不超过 logn,则此时查询修改的复杂度来到 O(logn)
通过按秩合并 + 路径压缩,查询、修改的时间复杂度将来到常熟级
Trie 树# 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
class Trie {
struct Node {
std :: array < int , 26 > children {}; // 子节点索引, 0 表示空
int prefixCount = 0 ; // 经过此节点的单词数
int endCount = 0 ; // 以此节点结尾的单词数
};
std :: vector < Node > nodes ;
static int idx ( char c ) { return c - 'a' ; }
public :
Trie () : nodes ( 1 ) {} // nodes[0] 为根节点
void insert ( std :: string_view word ) {
int cur = 0 ;
for ( char c : word ) {
int i = idx ( c );
if ( ! nodes [ cur ]. children [ i ]) {
nodes [ cur ]. children [ i ] = static_cast < int > ( nodes . size ());
nodes . emplace_back ();
}
cur = nodes [ cur ]. children [ i ];
++ nodes [ cur ]. prefixCount ;
}
++ nodes [ cur ]. endCount ;
}
bool search ( std :: string_view word ) const {
int cur = 0 ;
for ( char c : word ) {
int i = idx ( c );
if ( ! nodes [ cur ]. children [ i ]) return false ;
cur = nodes [ cur ]. children [ i ];
}
return nodes [ cur ]. endCount > 0 ;
}
bool startsWith ( std :: string_view prefix ) const {
int cur = 0 ;
for ( char c : prefix ) {
int i = idx ( c );
if ( ! nodes [ cur ]. children [ i ]) return false ;
cur = nodes [ cur ]. children [ i ];
}
return true ;
}
// 统计以 prefix 为前缀的单词数量
int countPrefix ( std :: string_view prefix ) const {
int cur = 0 ;
for ( char c : prefix ) {
int i = idx ( c );
if ( ! nodes [ cur ]. children [ i ]) return 0 ;
cur = nodes [ cur ]. children [ i ];
}
return nodes [ cur ]. prefixCount ;
}
// 删除单词(不负责检查单词是否存在)
void erase ( std :: string_view word ) {
int cur = 0 ;
for ( char c : word ) {
cur = nodes [ cur ]. children [ idx ( c )];
-- nodes [ cur ]. prefixCount ;
}
-- nodes [ cur ]. endCount ;
}
};
相比于传统的链表形式,数组版本的CPU缓存更加友好,只不过在删除方面比较劣势,不能做到真正的“析构”。
LRU# 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
// LRU
class LRUCache {
using ListNode = std :: pair < int , int > ;
public :
LRUCache ( int capacity ) : cap ( capacity ) {}
int get ( int key ) {
int value = - 1 ;
if ( map . find ( key ) != map . end ())
{
value = map [ key ] -> second ;
lists . splice ( lists . begin (), lists , map [ key ]);
map [ key ] = lists . begin ();
}
return value ;
}
void put ( int key , int value ) {
if ( map . find ( key ) != map . end ())
{
map [ key ] -> second = value ;
lists . splice ( lists . begin (), lists , map [ key ]);
map [ key ] = lists . begin ();
}
else
{
lists . push_front ({ key , value });
if ( lists . size () > cap )
{
auto it = lists . back ();
map . erase ( it . first );
lists . pop_back ();
}
map [ key ] = lists . begin ();
}
}
private :
int cap ;
std :: list < ListNode > lists ;
std :: unordered_map < int , std :: list < ListNode >:: iterator > map ;
};
// TODO LRU-K
二叉平衡树# 树形DP# 常见八股# 编译相关# 程序编译流程# 预处理(条件编译) –> 编译(汇编代码) –> 汇编(机器码) –> 链接(合并产物)
预处理:展开所有宏,处理所有条件编译指令,删除注释
编译:对源代码做词法、语法分析,生成模板代码,对constexpr求值,生成汇编代码
汇编:生成机器码,最终的目标文件中包含:
.text 段:代码段,用来保存生成的机器码.data / .bss 段:全局/静态变量(.data已初始化、.bss未初始化)符号表 :记录该文件定义和引用了哪些符号(函数名、变量名)重定位表 :记录哪些地址需要在链接时修正
此时的编译文件中包含的函数地址、全局变量地址在没有经过链接之前,都可以理解为是无效地址,因为这里生成的编译产物只是单独编译单元自娱自乐,他们还需要和其他编译单元结合、整理,才能生成最终的可用文件。
链接:合并所有的代码段,全局、静态变量段 ,对引用的函数地址进行重定位,写入真实的调用地址。生成可执行文件、库文件。
不同平台的生成产物对比 :
可执行文件:
Windows Linux 后缀 .exe无后缀 文件格式 PE (Portable Executable)ELF (Executable and Linkable Format)入口点 mainCRTStartup → 调用 main_start → __libc_start_main → main运行时依赖 MSVC Runtime (vcruntime140.dll 等) glibc (libc.so.6) 查看工具 dumpbin /headers app.exereadelf -h app / file app
静态库 (Static Library)
Windows Linux 后缀 .lib.a本质 多个 .obj 打包在一起的归档文件 多个 .o 打包在一起的归档文件 创建工具 lib.exear创建命令 lib /OUT:math.lib add.obj mul.objar rcs libmath.a add.o mul.o链接方式 链接时选取需要的 .obj 拷贝进可执行文件 同左 命名惯例 xxx.liblibxxx.a
动态库 (Dynamic/Shared Library)
Windows Linux 后缀 .dll (Dynamic Link Library).so (Shared Object)链接时需要 .lib(导入库 ).so 本身创建命令 cl /LD math.cpp → 生成 math.dll + math.libg++ -shared -fPIC -o libmath.so math.o运行时加载 LoadLibrary("math.dll")dlopen("libmath.so", RTLD_LAZY)符号可见性 需要 __declspec(dllexport/dllimport) 显式导出 默认全部导出(可用 -fvisibility=hidden 隐藏)
什么是“位置无关代码”?# 为什么代码会"依赖位置"?
一段普通的 C++ 代码编译成机器码后,通常会包含绝对地址引用 :
1
2
3
4
; 假设全局变量 g_count 被编译器分配在地址 0x00404000
; 非 PIC 代码:直接使用绝对地址
mov eax , [ 0x00404000 ] ; 读取 g_count 的值
call 0x00401200 ; 调用函数 foo(),绝对地址
如果这段代码被加载到了它"期望"的基地址(比如 0x00400000),一切正常。
但如果被加载到其他地址呢 ?比如对于 g_count 变量,其期望被加载到 0x00400000,但是程序实际启动时,他被操作系统映射到 0x7F200000,此时我再按照原本的映射逻辑去 400 地址寻找该变量,就会爆发UB,即:未定义错误。
这就是"位置相关代码"的问题:代码只能在特定地址运行 。
而**位置无关代码 (Position-Independent Code, PIC)**就是通过用相对地址替代绝对地址来规避地址被写死的问题:
1
2
3
; PIC 代码:使用 RIP 相对寻址 (x86-64)
mov eax , [ rip + 0x2A30 ] ; g_count 在"当前指令地址 + 0x2A30"处
call [ rip + 0x1B00 ] ; foo() 在"当前指令地址 + 0x1B00"处
无论代码被加载到哪个地址,指令与数据之间的相对偏移是固定的 ,所以总能正确访问。
对于静态库而言,由于其在链接阶段就能够确认所有符号的地址,没有链接器找不到的符号,所以链接器可以直接将用到的符号地址写死在生成文件中,比如文件会被加载到:0x0000040000这个地址,那我直接将该变量的地址标记成0x0000045000,后续所有的访问都去这里找,这样是没有问题的。
但是:文件一定会被加载到0x0000040000吗?链接器为什么如此肯定?
可执行文件加载地址
在比较古早的操作系统时代,还没有ASLR 的时候,所有可执行文件都被加载到固定的虚拟地址,但这会留下安全隐患,对于有恶意的攻击者来说,他能稳定知道你可执行文件的加载地址,就能精准构造攻击手段,非常不安全。
**ASLR(Address Space Layout Randomization,地址空间布局随机化)**是一种操作系统防御内存损坏漏洞的安全技术。它通过随机分配程序在内存中的关键区域(如堆、栈、动态链接库)位置,使攻击者难以预测目标地址,从而有效防范缓冲区溢出等攻击。
而在现代操作系统,通过使用 ASLR 技术,将可执行文件加载到随机地址,使得可执行文件每次被加载进内存时,虚拟地址的起始地址都是随机的。
但是这样不是就会影响到静态库的加载了吗?编译器在加载静态库时就不能肆意妄为的将符号的地址直接写成绝对地址了。所以对于现代编译器来说,所有的符号地址都会在链接的时候被写成相对地址,不依赖可执行文件或动态库的实际加载地址。
这里的相对地址(PIC),在不同平台下有不同的实现策略,在Linux环境下,程序编译时会默认开启 -fPIE 选项,从而在链接时能够为符号开启相对寻址,但是想要将静态库能够链接到动态库或可执行文件上,仍然需要开启 -fPIC 选项。
Linux:
PLT/GOT 与间接寻址
那既然对于现代编译器而言,所有的符号地址都会被写成相对地址,那我的静态库岂不是可以直接链接到动态库上,为什么还要多走一步,开启 -fPIC 选项呢?
这是因为:对于模块内部调用而言,调用的变量、函数都是确定的,函数在代码段的位置也是确定的,所以可以直接写成相对地址,通过偏移量来访问,程序在加载时会将整个模块都加载进来,不会影响到内部偏移量的正确性。
但是如果要跨模块调用,比如说我的可执行程序需要加载一个动态库,此时由于动态库的加载位置是不确定的,要等到程序开始运行时由链接器来加载,所以此时,原本暴力填写相对位置的方案也不奏效了,就需要一个新的方案,也就是:间接寻址 。而这个方案就需要 -fPIC 选项来开启。
GOT(Global Offset Table) — 访问跨模块全局变量
GOT 是一个位于数据段(.got / .got.plt)的指针数组,每个条目对应一个需要运行时解析的外部符号。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
代码段 (.text) 数据段 (.got)
只读,多进程共享 可写,每进程私有拷贝
┌──────────────────┐ ┌────────────────────┐
│ mov rax, │ │ GOT[0]: 0x0 │ ← 加载前为空
│ [rip + X] │──(rip+X)─>│ GOT[1]: 0x0 │
│ mov eax, [rax] │ │ GOT[2]: 0x0 │
└──────────────────┘ └────────────────────┘
不含任何绝对地址 动态链接器(ld-linux.so)
可以被多个进程共享 在加载时填入真实地址
同一份物理内存 │
▼
┌────────────────────┐
│ GOT[0]: 0x7F3A2010 │ ← 某外部变量的真实地址
│ GOT[1]: 0x7F3B4088 │
│ GOT[2]: 0x7F3C10A0 │
└────────────────────┘
PLT (Procedure Linkage Table) — 调用跨模块函数(延迟绑定)
PLT 在 GOT 的基础上增加了****延迟绑定 (Lazy Binding)*:函数地址不在加载时解析,而是在
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
第一次调用 printf():
app 代码 PLT stub GOT 条目 动态链接器
│ │ │ │
│ call PLT[n] │ │ │
│───────────────>│ jmp *GOT[n] │ │
│ │──────────────────────>│ (初始值: 指向 │
│ │ │ resolver stub) │
│ │ │──────────────────> │ _dl_runtime_resolve
│ │ │ │ 1. 查找 printf 地址
│ │ │ │ 2. 写入 GOT[n]
│ │ │ GOT[n] = 真实地址 │ 3. 跳转到 printf
│ │ │<──────────────────│
第二次调用 printf():
app 代码 PLT stub GOT 条目 printf()
│ │ │ │
│ call PLT[n] │ │ │
│───────────────>│ jmp *GOT[n] │ │
│ │──────────────────────>│ (已填入真实地址) │
│ │ │──────────────────>│ 直接执行
无需再次解析
延迟绑定 :一个程序可能链接了大量动态库中的函数,但实际运行中只使用其中一部分。延迟绑定避免了在启动时解析所有符号的开销,从而加快程序启动速度 。
可通过环境变量 LD_BIND_NOW=1 或链接选项 -z now 关闭延迟绑定,强制在加载时完成全部符号解析。这在安全敏感的场景中更常见(配合 -z relro 使 GOT 只读,防止 GOT 被攻击者篡改)。
Windows:
Windows 采用了与 Linux 截然不同的策略 :DLL 的代码段允许包含绝对地址,然后在加载时通过**重定位表 (.reloc)**修正。
1
2
3
4
5
6
7
PE Header:
ImageBase: 0x10000000 ← 链接器假定该 DLL 将加载到此地址
.reloc section: ← 重定位表,记录所有绝对地址引用的位置
偏移 0x1042: 需要修正
偏移 0x1067: 需要修正
偏移 0x10A3: 需要修正
...
当加载位置与假定位置相同时,则不需要修正,性能最优,针对函数的调用方式与Linux差不多。
语法相关# 四种cast的实现方式?# 虚函数# 虚函数创建时机:
虚函数表的生命周期分为两个阶段:
编译/链接期 —— vtable 的生成
编译器 在编译每个含虚函数的类时,会为该类生成一个 vtable(一个函数指针数组),存放在**目标文件(.o / .obj)**中。链接器 在链接时将 vtable 合并到最终的可执行文件/动态库中。vtable 的内容在程序运行前就已经完全确定,是只读的静态数据 。 生成规则(以 GCC/Clang 为例) :vtable 通常放在第一个非内联、非纯虚函数的定义所在的编译单元 中。如果所有虚函数都是内联的,则每个使用该类的编译单元都会生成一份 vtable,由链接器去重。
运行期 —— vptr 的设置
每个含虚函数的对象内部都有一个隐藏的指针 vptr (通常在对象内存布局的最开头)。 在构造函数执行期间 ,编译器会插入代码将 vptr 指向当前正在构造的类的 vtable: 1
2
3
4
5
6
7
8
9
10
11
// 编译器在构造函数中隐式插入的伪代码
Derived :: Derived () {
// 1. 先调用基类构造函数
Base :: Base (); // 此时 vptr 指向 Base::vtable
// 2. 编译器插入:将 vptr 更新为 Derived 的 vtable
this -> vptr = & Derived :: vtable ;
// 3. 执行 Derived 构造函数体
...
}
这就是为什么在基类构造函数中调用虚函数不会表现出多态 ——此时 vptr 还指向基类的 vtable。
虚函数存储位置:
内容 存储位置 生命周期 vtable (函数指针数组)只读数据段 (.rodata 或 .rdata)与程序一样长 vptr (指向 vtable 的指针)对象内部 (通常是对象的第一个成员)与对象一样长
Linux (GCC/Clang) :vtable 通常在 .rodata 段(只读数据段),有时在 .data.rel.ro(需要重定位的只读数据段,加载完成后变为只读)。Windows (MSVC) :vtable 通常在 .rdata 段。vtable 本身是全局唯一 的,每个类只有一份(不是每个对象一份);每个对象只持有一个 vptr(8 字节,64 位系统)。 手动调用虚函数:
对于如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class Base1 {
public :
virtual void func1 () { std :: cout << "Base1::func1()" << std :: endl ; }
virtual void func2 () { std :: cout << "Base1::func2()" << std :: endl ; }
int base1_data = 0x11 ;
};
class Base2 {
public :
virtual void func3 () { std :: cout << "Base2::func3()" << std :: endl ; }
virtual void func4 () { std :: cout << "Base2::func4()" << std :: endl ; }
int base2_data = 0x22 ;
};
class Derived : public Base1 , public Base2 {
public :
// 重写 Base1 的 func1
void func1 () override { std :: cout << "Derived::func1()" << std :: endl ; }
// 重写 Base2 的 func3
void func3 () override { std :: cout << "Derived::func3()" << std :: endl ; }
// Derived 自己的虚函数
virtual void func5 () { std :: cout << "Derived::func5()" << std :: endl ; }
int derived_data = 0x33 ;
};
可以通过虚函数指针,找到虚函数表,直接对虚函数进行调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
Derived * pDerived = & d ;
// vptr1: 位于对象起始位置(Base1 子对象的 vptr)
uintptr_t * vptr1_addr = reinterpret_cast < uintptr_t *> ( pDerived );
uintptr_t * vtable1 = reinterpret_cast < uintptr_t *> ( * vptr1_addr );
// vptr2: 位于 Base2 子对象起始位置
uintptr_t * vptr2_addr = reinterpret_cast < uintptr_t *> ( pBase2 );
uintptr_t * vtable2 = reinterpret_cast < uintptr_t *> ( * vptr2_addr );
std :: cout << "--- vtable 指针 ---" << std :: endl ;
printf ( "vptr1 (Base1/Derived 主表) 地址: %p, 值: %p \n " , ( void * ) vptr1_addr , ( void * ) vtable1 );
printf ( "vptr2 (Base2 子表) 地址: %p, 值: %p \n " , ( void * ) vptr2_addr , ( void * ) vtable2 );
std :: cout << std :: endl ;
// ----------------------------------------------------------
// 3. 通过 vtable 手动调用虚函数
// ----------------------------------------------------------
std :: cout << "--- 通过 vtable1 (主表) 调用函数 ---" << std :: endl ;
// vtable1 布局 (GCC/Clang, MSVC 类似但细节不同):
// [0] -> Derived::func1() (重写了 Base1::func1)
// [1] -> Base1::func2() (未重写,继承)
// [2] -> Derived::func5() (Derived 自己的虚函数,追加到主表末尾)
std :: cout << "vtable1[0]: " ;
printf ( "地址=%p " , ( void * ) vtable1 [ 0 ]);
// 用成员函数指针的方式调用(需要 this 指针)
using MemFunc = void ( * )( Derived * );
MemFunc fn ;
fn = reinterpret_cast < MemFunc > ( vtable1 [ 0 ]);
fn ( pDerived ); // 应该输出 Derived::func1()
std :: cout << "vtable1[1]: " ;
printf ( "地址=%p " , ( void * ) vtable1 [ 1 ]);
fn = reinterpret_cast < MemFunc > ( vtable1 [ 1 ]);
fn ( pDerived ); // 应该输出 Base1::func2()
// 输出:
// --- vtable 指针 ---
// vptr1 (Base1/Derived 主表) 地址: 00000034CE74F6D8, 值: 00007FF63665BE50
// vptr2 (Base2 子表) 地址: 00000034CE74F6E8, 值: 00007FF63665BE78
// --- 通过 vtable1 (主表) 调用函数 ---
// vtable1[0]: 地址=00007FF6366511D1 Derived::func1()
// vtable1[1]: 地址=00007FF636651168 Base1::func2()
// vtable1[2]: 地址=00007FF636651046 Derived::func5()
Qt Thread# Qt Plugin# QModel/View# 设计模式:
策略模式 :通过Delegate进行绘制注册观察者模式 :数据更新时通知View ,由View再去驱动Delegate进行绘制。将数据与UI解耦。开闭原则( Open-Closed Principle,OCP) :对扩展开放,对修改关闭。即对于新增功能尽量去新增代码而不是修改老代码。MVC
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
1. 自定义 QAbstractTableModel(最高频考点)
- data() 多角色处理 (DisplayRole, EditRole, BackgroundRole, TextAlignmentRole...)
- flags() 控制可编辑/可选择
- setData() 编辑数据 + dataChanged 信号
- headerData() 自定义表头
- rowCount() / columnCount()
- insertRows() / removeRows() + beginXxx/endXxx 通知机制
2. QSortFilterProxyModel(代理模型:排序/过滤)
- 设置过滤列、正则表达式
- 自定义排序规则 (lessThan)
- 代理索引 ↔ 源索引的映射 (mapToSource / mapFromSource)
3. 自定义 QStyledItemDelegate(委托/代理)
- createEditor() 创建编辑器控件
- setEditorData() 模型 → 编辑器
- setModelData() 编辑器 → 模型
- updateEditorGeometry()
- paint() 自定义绘制(进度条示例)
4. Model/View 架构核心概念
- QModelIndex 的角色与使用
- 数据角色 (Qt::ItemDataRole) 体系
- 信号通知机制 (dataChanged, layoutChanged, rowsInserted...)
QGraphicsView# 1
2
3
4
5
6
7
8
9
10
11
12
QGraphicsItem
- boundingRect(): 返回 Item 的包围矩形 (用于裁剪、碰撞粗检测、重绘区域)
- paint(): 具体的绘制逻辑
- shape(): 返回精确的形状路径 (用于碰撞精确检测和鼠标拾取)
默认实现返回 boundingRect() 的矩形, 对非矩形 Item 应该重写
QGraphicsObject = QGraphicsItem + QObject
区别(QGraphicsItem 与 QGraphicsObject):
- 支持信号和槽 (Q_OBJECT)
- 支持 Q_PROPERTY → QPropertyAnimation
- 有额外的 QObject 开销 (元对象系统)
- 已内置 pos, rotation, scale, opacity 等动画属性
QStyle# 如你所见,这是我拿到的Hazel游戏引擎的付费3D版的源码,我之前跟随Hazel开放出来的视频做了一个2D版本的轻量游戏引擎,代码位置在:D:\Data\Project\Yuicy 路径下,具体的仓库结构都相似,但是缺少了3D功能,缺少了游戏引擎应该有的编辑功能,并且他的引擎使用的 脚本是 C#脚本,我这边采用的是Lua脚本作为我的引擎脚本。
OpenGL# 函数记录# Buffer# glBufferData# glBufferData是用来向GPU申请缓存的函数:
1
2
3
4
5
6
void glBufferData (
GLenum target ,
GLsizeiptr size ,
const void * data ,
GLenum usage
);
其中target不同,用处不同:
target 含义 GL_ARRAY_BUFFER顶点数据 GL_ELEMENT_ARRAY_BUFFER索引数据 GL_UNIFORM_BUFFERuniform 数据 GL_SHADER_STORAGE_BUFFER计算数据 GL_PIXEL_UNPACK_BUFFER纹理上传
针对data参数,传入非空时会将数据从CPU copy到 GPU,传NULL时会等待glBufferSubData或glMapBuffer写数据(与usage参数无关)。
最后一个usage参数不会改变 API 行为,其作用是调整OpenGL驱动对GPU缓存的优化策略:
usage 含义 GL_STATIC_DRAW数据几乎不变 GL_DYNAMIC_DRAW会偶尔修改 GL_STREAM_DRAW每帧更新
所以,对于GL_STATIC_DRAW,也可以在申请缓存时将data字段传NULL,但是会导致每次调用glBufferSubData时消耗增加。
glBufferSubData 与 glMapBuffer# glBufferSubData
当glBufferData 的数据部分传空时需要使用glBufferSubData进一步动态更新数据:
1
2
glBindBuffer ( GL_ARRAY_BUFFER , vbo );
glBufferSubData ( GL_ARRAY_BUFFER , 0 , size , data );
这里会存在一个pipeline stall(或CPU stall),即GPU流水线上堆积了任务,正在使用该缓存,但是此时CPU又要进行写入,这就会造成CPU的等待,可以通过buffer orphaning(缓存孤立)来缓解这种停顿现象:
1
2
3
glBindBuffer ( GL_ARRAY_BUFFER , vbo );
glBufferData ( GL_ARRAY_BUFFER , size , NULL , GL_DYNAMIC_DRAW );
glBufferSubData ( GL_ARRAY_BUFFER , 0 , size , data );
glMapBuffer
1
2
3
4
glBindBuffer ( GL_ARRAY_BUFFER , vbo );
void * ptr = glMapBuffer ( GL_ARRAY_BUFFER , GL_WRITE_ONLY );
// use ptr to copy data
glUnmapBuffer ( GL_ARRAY_BUFFER );
可以直接将数据从文件拷贝到共享buffer,减少拷贝?(是否可以类比于Linux下的mmap?)
glMapBuffer 与 glBufferSubData,返回 ·SteveStreeting.com
有博客提到在大数据量的情况下glMapBuffer性能高于glBufferSubData,并且存在一个阈值。
glBufferSubData会造成两次数据拷贝:
从内存到驱动内部的 临时缓冲区 (在合适的时机)从临时缓冲区通过 DMA 传输到GPU显存 而glMapBuffer在一次数据传输时,可能只会涉及到0次或1次的数据拷贝“
CPU将数据 通过 CPU 页表直接映射到 GPU 显存的物理地址(通过 PCIe BAR进行映射,需要开销),无额外拷贝开销 或,直接将数据写入到 驱动的 DMA缓冲区中
由于 直接拷贝 依赖页表的地址映射,所以写入效率未必会高,具体应该依赖于GPU的驱动实现。对于独立显卡,可能更依赖于后者(直接将数据写入DMA缓冲,绘制时由DMA将数据拷贝到GPU显存),对于集成显卡,可能更多采用第一种实现,即直接做地址映射,并通过CPU进行数据拷贝
glEnableVertexAttribArray 和 glVertexAttribPointer# 函数原型:
1
2
3
4
5
6
7
8
9
10
11
12
13
// 启用 index 指定的顶点属性数组
// layout(location = 0)
void glEnableVertexAttribArray ( GLuint index );
// 声明顶点属性
void glVertexAttribPointer (
GLuint index , // arrtibute index
GLint size , // 属性由几个分量组成
GLenum type , // 每个分量的数据类型
GLboolean normalized , // 是否将数据做归一化处理
GLsizei stride , // 步长,通常传入所有顶点数据的长度之和
const void * pointer // 起始偏移量
);
对于 glVertexAttribPointer 的 type类型,当类型为整形 时,需要使用 glVertexAttribIPointer来正确传递数据,为double 时,建议使用:glVertexAttribLPointer。
Draw# glDrawElements 和 glDrawArrays# glDrawArrays:按顺序直接取顶点
1
void glDrawArrays ( GLenum mode , GLint first , GLsizei count );
常见的图元类型:
1
2
3
4
5
6
GL_POINTS
GL_LINES
GL_LINE_STRIP
GL_TRIANGLES
GL_TRIANGLE_STRIP
GL_TRIANGLE_FAN
参数 first 表示从VBO的什么位置开始,count 表示绘制几个顶点,按照 mode 方式进行组装。
glDrawElements:先读索引,再按索引去取顶点
1
void glDrawElements ( GLenum mode , GLsizei count , GLenum type , const void * indices );
与 glDrawArrays 的区别在于,他对顶点的要求只有个数,拿到个数后,会去EBO中按照EBO中的值进行顶点组装。
type 参数为索引类型,OpenGL要求索引类型必须为无符号整形。
indices 表示在索引缓冲区的起始偏移量,一般传 nullptr 即可。
Texture# glGenTextures、glActiveTexture、glBindTexture 创建、绑定纹理句柄# 1
2
3
4
5
6
7
8
// OpenGL 3.x
glGenTextures ( 1 , & tex );
glActiveTexture ( GL_TEXTURE3 ); // 选择当前活动纹理单元 (GL_TEXTURE0 ~ GL_TEXTURE31)
glBindTexture ( GL_TEXTURE_2D , tex );
glTexParameteri ( GL_TEXTURE_2D , ...); // 针对当前 Unit 当前 GL_TEXTURE_TYPE 进行操作
glTexImage2D ( GL_TEXTURE_2D , ...);
glGenerateMipmap ( GL_TEXTURE_2D );
1
2
3
void glGenTextures ( GLsizei n , GLuint * textures ); // 返回 n 个纹理句柄(不保证连续)
void glActiveTexture ( GLenum texture ); // 接下来将要编辑哪个纹理Unit
void glBindTexture ( GLenum target , GLuint texture ); // 将当前纹理对象绑定到某个纹理类型
纹理单元的类型有:
1
2
3
GL_TEXTURE_2D
GL_TEXTURE_CUBE_MAP
GL_TEXTURE_2D_ARRAY
对于新的OpenGL,接口风格有所变动:
1
2
3
4
5
6
7
8
9
// OpenGL 4.x
glCreateTextures ( GL_TEXTURE_2D , 1 , & tex ); // 创建时就将纹理句柄和纹理target绑定(全生命周期绑定)
glTextureStorage2D ( tex , levels , GL_RGBA8 , w , h );
glTextureSubImage2D ( tex , 0 , 0 , 0 , w , h , GL_RGBA , GL_UNSIGNED_BYTE , pixels );
glTextureParameteri ( tex , GL_TEXTURE_MIN_FILTER , GL_LINEAR_MIPMAP_LINEAR );
glGenerateTextureMipmap ( tex );
glBindTextureUnit ( 3 , tex ); // 将纹理绑定到Unit_3 纹理类型 在创建时就已经绑定
glTexImage2D 分配纹理存储# 1
2
3
4
5
6
7
8
9
10
11
12
// OpenGL 3.x
// 需要先Bind再进行分配
glBindTexture ( GL_TEXTURE_2D , textureID );
glTexImage2D ( GL_TEXTURE_2D ,
0 , // mipmap 层级
GL_RGBA8 , // 内部格式
width , height ,
0 , // border(必须为 0)
GL_RGBA , // 像素数据格式
GL_UNSIGNED_BYTE , // 像素分量类型
nullptr // 数据指针(nullptr = 只分配不填充)
);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// OpenGL 4.x
// 创建固定大小的纹理,不可修改尺寸和格式
glTextureStorage2D ( textureID ,
1 , // mipmap 层级数(1 = 不生成 mipmap)
GL_RGBA8 , // 内部格式(GPU 端存储格式)
width , height // 尺寸
);
// glTextureParameteri 设置纹理属性
// 通过 glTextureSubImage2D 上传纹理数据
glTextureSubImage2D (
GLuint texture , // 句柄
GLint level , // mipmap层级
GLint xoffset , // 偏移量
GLint yoffset ,
GLsizei width , // 数据宽高
GLsizei height ,
GLenum format , // 数据格式:GL_RGB、GL_RGBA、...
GLenum type , // 数据类型
const void * pixels // 纹理数据
)
传统的 glTexImage2D 在参数中需要传入纹理的宽高和数据,这就意味着可以多次调用该函数来修改纹理尺寸、格式,同时完成数据分配和上传
glTexImage2D 既做分配又做上传,如果频繁调用会导致 GPU 端反复重建纹理内存。在需要频繁更新数据但不改变尺寸的场景中(如视频流),应使用 glTexStorage2D + glTexSubImage2D 的组合。
内部格式 通道 每通道位数 用途 GL_RGBA8RGBA 8-bit 标准颜色纹理 GL_RGB8RGB 8-bit 无 Alpha 颜色 GL_RGBA16FRGBA 16-bit float HDR 渲染 GL_R32IR 32-bit int Entity ID 拾取 GL_DEPTH24_STENCIL8D+S 24+8 深度/模板缓冲
glTexParameteri 纹理采样参数# 传统纹理采样接口:
1
2
3
4
5
6
7
// OpenGL 3.x
glBindTexture ( GL_TEXTURE_2D , textureID ); // 绑定纹理句柄
glTexParameteri ( GL_TEXTURE_2D , GL_TEXTURE_MIN_FILTER , GL_LINEAR ); // 缩小过滤器
glTexParameteri ( GL_TEXTURE_2D , GL_TEXTURE_MAG_FILTER , GL_NEAREST ); // 放大过滤器
glTextureParameteri ( textureID , GL_TEXTURE_WRAP_S , GL_REPEAT ); // 环绕模式设置
glTextureParameteri ( textureID , GL_TEXTURE_WRAP_T , GL_REPEAT );
// ...
1
2
3
// OpenGL 4.x
glTextureParameteri ( textureID , GL_TEXTURE_MIN_FILTER , GL_LINEAR );
// ...
这里接口参数变化不大,只是在设置纹理属性的时候省略的 Bind 的步骤(也不需要在参数中传入纹理类型)。
环绕模式 效果 适用场景 GL_REPEAT重复平铺 地面纹理、瓦片 GL_MIRRORED_REPEAT镜像重复 对称纹理 GL_CLAMP_TO_EDGE钳制到边缘像素 FBO 附件(防止边缘渗色) GL_CLAMP_TO_BORDER超出部分用指定颜色填充 阴影贴图
FBO 附件必须使用 GL_CLAMP_TO_EDGE。如果使用 GL_REPEAT,后处理 Shader 在纹理边缘采样时会读到对面的像素,导致画面边缘出现伪影。
Shader# FrameBuffer# 1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 将纹理附加为颜色附件 0
glFramebufferTexture2D ( GL_FRAMEBUFFER ,
GL_COLOR_ATTACHMENT0 , // 附件点
GL_TEXTURE_2D , // 纹理目标
textureID , // 纹理 ID
0 // mipmap 层级
);
// 将纹理附加为深度/模板附件
glFramebufferTexture2D ( GL_FRAMEBUFFER ,
GL_DEPTH_STENCIL_ATTACHMENT ,
GL_TEXTURE_2D ,
depthTextureID ,
0
);
1
2
3
4
5
6
7
8
// 告诉 OpenGL 同时渲染到多个颜色附件
GLenum buffers [] = { GL_COLOR_ATTACHMENT0 , GL_COLOR_ATTACHMENT1 ,
GL_COLOR_ATTACHMENT2 , GL_COLOR_ATTACHMENT3 };
glDrawBuffers ( 4 , buffers );
// 在Shader中通过out来将不同的数据输出到不同的附件中
layout ( location = 0 ) out vec4 o_Color ; // → GL_COLOR_ATTACHMENT0
layout ( location = 1 ) out int o_EntityID ; // → GL_COLOR_ATTACHMENT1
需要注意,使用 glCheckFramebufferStatus(GL_FRAMEBUFFER) 检查帧缓冲的配置完整性失败时,常见的失败原因如下:
原因 解决方法 没有附加任何附件 至少附加一个颜色或深度附件 附件尺寸不一致 所有附件保持相同宽高 内部格式不支持 检查驱动对该格式的支持 仅深度时未设置 glDrawBuffer(GL_NONE) 无颜色附件时必须显式声明
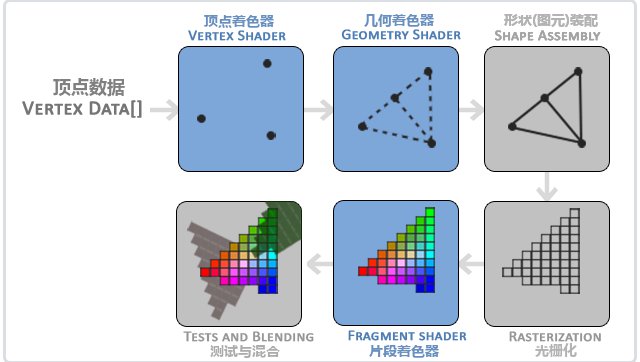
基本概念# 渲染流程# CPU端:
构建顶点数据:Position、Color 创建VAO、VBO、EBO(可选) 绑定Shader,设置Uniform数据 Draw Call GPU端
执行顶点着色器,在顶点着色器中做坐标变换 将输入的顶点组成图元(图元装配) 对图元做光栅化处理,整理图元覆盖到的片元类似于对连续的图形做离散化,离散成多个小矩形——像素 对输入的顶点数据进行 重心坐标插值,并将插值后的数据作为 片段着色器的 in 变量 执行片段着色器(以像素为单位),做纹理采样等工作,并输出片段颜色 深度/模板测试 颜色混合 根据当前绑定的FBO决定最终输出的位置,是否分别输出颜色和深度缓冲
CPU只能控制准备的数据、Shader、绘制的位置,对于GPU的绘制流程,只能通过着色器进行干预。
在任何绘制之前,需要一次性创建好 VBO、VAO、EBO、Shader、纹理 等 GPU 资源。
1 创建缓冲对象(VBO / EBO)
1
2
3
4
5
// ═══ VBO 存储顶点数据 ═══
GLuint vbo ;
glCreateBuffers ( 1 , & vbo ); // 创建缓冲对象
glBindBuffer ( GL_ARRAY_BUFFER , vbo ); // 绑定为顶点缓冲
glBufferData ( GL_ARRAY_BUFFER , size , nullptr , GL_DYNAMIC_DRAW ); // 分配显存,不填充数据
参数 含义 GL_ARRAY_BUFFER绑定点:顶点属性数据 GL_ELEMENT_ARRAY_BUFFER绑定点:索引数据(EBO) GL_STATIC_DRAW数据只上传一次,不再修改 GL_DYNAMIC_DRAW数据会频繁更新(批处理渲染常用)
1
2
3
4
5
6
cpp
// ═══ EBO 存储索引 ═══
GLuint ebo ;
glCreateBuffers ( 1 , & ebo );
glBindBuffer ( GL_ELEMENT_ARRAY_BUFFER , ebo );
glBufferData ( GL_ELEMENT_ARRAY_BUFFER , count * sizeof ( uint32_t ), indices , GL_STATIC_DRAW );
对于批处理,可以一次性分配一个足够大的空VBO,并在每次批处理时动态上传 动态大小 的VBO数据
(EBO使用GL_STATIC_DRAW做固定大小分配)。
1
2
glBufferData ( GL_ARRAY_BUFFER , 80000 * sizeof ( QuadVertex ), nullptr , GL_DYNAMIC_DRAW ); // VBO
glBufferData ( GL_ELEMENT_ARRAY_BUFFER , count * sizeof ( uint32_t ), indices , GL_STATIC_DRAW ); // EBO
2 创建VAO(存储VBO数据描述,VBO句柄、EBO句柄)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
GLuint vao ;
glCreateVertexArrays ( 1 , & vao );
glBindVertexArray ( vao );
// 绑定 VBO 后,告诉 OpenGL 如何解读其中的数据
glBindBuffer ( GL_ARRAY_BUFFER , vbo );
// 属性 0: Position (vec3, 从偏移 0 开始)
glEnableVertexAttribArray ( 0 );
glVertexAttribPointer ( 0 , // 属性索引(对应 Shader 中 layout(location = 0))
3 , // 分量数(vec3 = 3 个 float)
GL_FLOAT , // 数据类型
GL_FALSE , // 是否归一化
sizeof ( QuadVertex ), // 步长(一个完整顶点的字节数)
( const void * ) 0 // 偏移量(该属性在顶点中的起始位置)
);
// 属性 1: Color (vec4, 从偏移 12 开始)
glEnableVertexAttribArray ( 1 );
glVertexAttribPointer ( 1 , 4 , GL_FLOAT , GL_FALSE , sizeof ( QuadVertex ), ( const void * ) 12 );
// ... 更多属性 ...
3 准备顶点数据、每帧动态上传数据
初始化时用 glBufferData(... nullptr, GL_DYNAMIC_DRAW) 预分配大缓冲,之后每帧只用 glBufferSubData 填入实际使用的部分,避免了每帧重新分配显存的开销。
4 准备Shader
Vertex Shader:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
layout ( location = 0 ) in vec3 a_Position ; // ← VAO 属性 0
layout ( location = 1 ) in vec4 a_Color ; // ← VAO 属性 1
layout ( location = 2 ) in vec2 a_TexCoord ; // ← VAO 属性 2
layout ( location = 3 ) in float a_TexIndex ; // ← VAO 属性 3(纹理槽编号)
layout ( location = 4 ) in float a_TilingFactor ; // ← VAO 属性 4
uniform mat4 u_ViewProjection ; // 视图-投影矩阵(相机)
void main () {
// 向下传递给 Fragment Shader
v_Color = a_Color ;
v_TexCoord = a_TexCoord ;
v_TexIndex = a_TexIndex ;
v_TilingFactor = a_TilingFactor ;
// 核心变换:模型坐标 → 裁剪坐标
gl_Position = u_ViewProjection * vec4 ( a_Position , 1.0 );
}
Fragment Shader:
1
2
3
4
5
6
7
8
9
10
11
uniform sampler2D u_Textures [ 32 ]; // 32 个纹理采样器
void main () {
vec4 texColor = v_Color ;
// 根据纹理槽编号采样对应纹理
switch ( int ( v_TexIndex )) {
case 0 : texColor *= texture ( u_Textures [ 0 ], v_TexCoord * v_TilingFactor ); break ;
case 1 : texColor *= texture ( u_Textures [ 1 ], v_TexCoord * v_TilingFactor ); break ;
// ... case 2-31 ...
}
color = texColor ;
}
sampler2D u_Textures[32] 中的每个元素是一个 int,值为纹理单元编号(0-31)。这样同一个 Draw Call 中不同的 Quad 可以通过 a_TexIndex 从不同纹理采样。
5 逐帧更新 Uniform
1
2
3
4
5
6
7
8
9
// 设置相机矩阵
s_Data . TextureShader -> Bind (); // glUseProgram(programID)
s_Data . TextureShader -> SetMat4 ( "u_ViewProjection" , viewProj );
// 底层: glGetUniformLocation + glUniformMatrix4fv
// 初始化时设置纹理采样器数组
int samplers [ 32 ] = { 0 , 1 , 2 , ..., 31 };
shader -> SetIntArray ( "u_Textures" , samplers , 32 );
// 底层: glUniform1iv — 告诉每个 sampler 对应哪个纹理单元
6 绘制调用
1
2
3
4
5
6
7
8
9
10
11
void Renderer2D :: Flush () {
if ( s_Data . QuadIndexCount == 0 ) return ;
// 1. 绑定所有使用到的纹理到对应的纹理单元
// 这里的 TextureSlots 为每次 DrawQuad 时传入的智能指针
for ( uint32_t i = 0 ; i < s_Data . TextureSlotIndex ; i ++ )
s_Data . TextureSlots [ i ] -> Bind ( i ); // glBindTextureUnit(i, textureID)
// 2. 发起 Draw Call
RenderCommand :: DrawIndexed ( s_Data . QuadVertexArray , s_Data . QuadIndexCount );
}
glDrawElements — 索引绘制
1
2
3
4
5
6
7
vertexArray -> Bind (); // glBindVertexArray(vao) — 恢复所有顶点属性配置
glDrawElements (
GL_TRIANGLES , // 图元类型
indexCount , // 索引数量(每个 Quad 6 个)
GL_UNSIGNED_INT , // 索引类型
nullptr // 偏移(从 EBO 首部开始)
);
glDrawElements 调用后,控制权从 CPU 转移到 GPU。接下来的所有阶段(顶点着色、光栅化、片元着色等)全部由 GPU 硬件并行执行。
7 Vertex Shader 顶点着色器
对每个顶点执行一次,主要完成顶点坐标变化
8 图元装配、裁剪
超出 NDC 范围 [-1, 1] 的图元会被自动裁剪。
9 光栅化
将三角形扫描转换 为离散的片元(Fragment) ——每个片元对应屏幕上的一个像素候选。
光栅化还会对 Vertex Shader 的输出做插值 。
10 Fragment Shader(片元着色)
对每个片元执行一次 (并行),是管线中最耗时 的阶段。
11 模板测试、深度测试、混合
12 FBO
使用FBO改变渲染输出对象,将原本要输出到屏幕的数据转为输出到纹理缓冲中,用来做特效处理。
MVP矩阵及相关计算过程# 一些基础:
点、叉乘
线性变换
齐次坐标(homegenous coordinates)
:一种用N+1个数来表示N维坐标的方式
传统二维向量的坐标变换(仿射变换):
[ x ‘ y ‘ ] = [ a b c d ] ∗ [ x y ] + ∗ [ t x t y ]
\begin{bmatrix}
x^`\\
y^`
\end{bmatrix}
=
\begin{bmatrix}
a & b \\
c & d
\end{bmatrix}
*
\begin{bmatrix}
x \\
y
\end{bmatrix}
+
*
\begin{bmatrix}
t_x \\
t_y
\end{bmatrix}
[ x ‘ y ‘ ] = [ a c b d ] ∗ [ x y ] + ∗ [ t x t y ] 引入其次坐标:
[ x ‘ y ‘ 1 ‘ ] = [ a b t x c d t y 0 0 1 ] [ x y 1 ]
\begin{bmatrix}
x^`\\
y^`\\
1^`
\end{bmatrix}
=
\begin{bmatrix}
a & b & t_x\\
c & d & t_y\\
0 & 0 & 1
\end{bmatrix}
\begin{bmatrix}
x \\
y \\
1
\end{bmatrix}
x ‘ y ‘ 1 ‘ = a c 0 b d 0 t x t y 1 x y 1 在其次坐标中,一个 Point(x, y, w),可以看作:
[ x / w y / w 1 ] ( w ! = 0 )
\begin{bmatrix}
x/w\\
y/w\\
1
\end{bmatrix}
(w != 0)
x / w y / w 1 ( w ! = 0 ) 旋转、平移、缩放,计算时从右向左进行矩阵乘法。
Model:模型矩阵 ,物体的大小、坐标、旋转属性,汇聚成一个Model矩阵,这里的物体坐标可以任意指定原点 View:视图矩阵(观察矩阵) ,即相机的位置、朝向以及正方向,通过 glm::LoogAt 进行配置 Projection:投影矩阵 ,又分为正交投影和透视投影,有专门的接口来做这件事,基础的区别就是 正交的w分量为1,即Z轴坐标不会影响到x、y分量的值。 着色器# 后处理# MSAA(多重采样纹理)# 光栅化阶段判断一个像素是否被三角形覆盖时,默认只检查像素中心点 这一个位置。如果三角形的边恰好经过该像素,中心点的“覆盖/不覆盖”只有 0 和 1 两种结果,就会导致最终绘制的图形边缘存在锯齿。
而MSAA通过将每个像素细分为多个采样点(Sample) ,以 4x MSAA 为例:
1
2
3
4
5
6
7
8
9
普通渲染(1 sample/pixel) 4x MSAA(4 samples/pixel)
┌─────────────────┐ ┌─────────────────┐
│ │ │ ○ ● │
│ ● │ 只判断一个点 │ │ 判断 4 个点
│ (中心点) │ → 0 或 1 │ ● ○ │ → 0/4, 1/4, 2/4...
│ │ │ │
└─────────────────┘ └─────────────────┘
● = 被三角形覆盖
○ = 未被覆盖
MSAA 的关键流程:
阶段 普通渲染 MSAA 渲染 覆盖测试 1 个采样点 N 个采样点,分别判断覆盖 Fragment Shader 执行 每像素 1 次 每像素仍然只执行 1 次 ✓颜色存储 1 份颜色/像素 N 份颜色/像素(每个 sample 独立) 深度/模板测试 1 次 N 次(每 sample 独立) Resolve(解析) 不需要 将 N 个 sample 平均为最终颜色
MSAA 的性能优势在于 Fragment Shader 只执行一次 ,然后将结果写入所有被覆盖的 sample。这比 SSAA(超采样,Shader 也执行 N 次)高效得多。代价是显存占用增加 N 倍。
多采样纹理需要使用 GL_TEXTURE_2D_MULTISAMPLE 进行纹理声明,同时他不能被普通 Shader 直接采样 ——因为每个像素有 N 个 sample,texture() 函数不知道该返回哪个。
解决方案是 Resolve(解析) ——将多个 sample 平均合并为单一颜色:
1
2
3
4
5
6
7
8
9
10
// Resolve:将 MSAA FBO 拷贝/平均到普通 FBO
glBindFramebuffer ( GL_READ_FRAMEBUFFER , msaaFBO ); // 读取源
glBindFramebuffer ( GL_DRAW_FRAMEBUFFER , resolveFBO ); // 写入目标
glBlitFramebuffer (
0 , 0 , width , height , // 源矩形
0 , 0 , width , height , // 目标矩形
GL_COLOR_BUFFER_BIT , // 拷贝颜色
GL_NEAREST // 过滤模式(多采样resolve时忽略)
);
在 Shader 中读取多采样纹理需要使用 sampler2DMS 和 texelFetch(tex, ivec2(coord), sampleIndex),手动遍历每个 sample 并平均。但这比 glBlitFramebuffer 更复杂,通常只在自定义 resolve 逻辑(如 tone mapping 前 resolve)时使用。
MSAA创建:
1
2
3
4
5
6
7
8
9
10
// 创建多采样纹理(DSA)
glCreateTextures ( GL_TEXTURE_2D_MULTISAMPLE , 1 , & textureID );
// 分配存储(注意:没有 mipmap,没有过滤参数)
glTexImage2DMultisample ( GL_TEXTURE_2D_MULTISAMPLE ,
samples , // 采样数(4, 8, 16...)
GL_RGBA8 , // 内部格式
width , height ,
GL_FALSE // fixedSampleLocations
);
fixedSampleLocations 参数:
值 含义 GL_TRUE所有像素使用相同的采样点布局(性能更好,兼容性更好) GL_FALSE驱动可以自由选择每个像素的采样点位置(质量可能稍好)
多采样纹理 vs 普通纹理的限制
特性 普通纹理 GL_TEXTURE_2D 多采样纹理 GL_TEXTURE_2D_MULTISAMPLE 过滤参数 ✅ MIN/MAG_FILTER ❌ 不支持 环绕模式 ✅ WRAP_S/T ❌ 不支持 Mipmap ✅ 支持 ❌ 不支持 texture() 采样✅ ❌ 需用 texelFetch() 后处理输入 ✅ 直接使用 ❌ 需先 Resolve 显存占用 1× N× samples
Lua# ImGUI# 场景问题# ECS# 维度 传统 OOP 继承 ECS 数据组织 对象持有自己的所有数据 数据按组件类型分组存储(SoA) 行为定义 虚函数继承 System 函数遍历满足条件的实体 内存布局 对象分散在堆上,缓存不友好 同类型组件连续存储,缓存友好 扩展性 需要修改/继承类 组合不同 Component 即可,符合组合优于继承原则
对于传统的OOP,通过继承来进行功能实现 ,很容易造成接口、数据冗余 对于游戏这种 高性能要求的场景,即使通过 GameObject + Component 的方式,虽然满足了组合优于继承的原则,但是对于 CPU Cache 仍然并不友好。 ECS通过:组件连续存储 + 实体Id绑定,来实现更好的缓存友好,更高效的组件查询,并且可优化空间较大(对于组件查询来说)
稀疏集合:# 1
2
3
4
5
6
7
template < typename Component >
struct ComponentPool {
std :: vector < int > sparse ; // 下标=EntityID, 值=dense中的位置
std :: vector < int > dense ; // 紧凑存储拥有此组件的EntityID
std :: vector < Component > components ; // 与 dense 一一对应的组件数据
int count = 0 ;
};
通过直接在 sparse 中查询 组件ID,能够做到O(1)的存取组件,并且遍历组件友好,对于 sparse,还可以通过分页的方式进行优化,避免由于 组件ID 过大 导致的内存浪费。
eg:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// 简化版,展示核心思路
template < typename Entity >
class basic_sparse_set {
static constexpr auto page_size = 4096 ;
// 页表:vector of unique_ptr<Entity[]>
std :: vector < std :: unique_ptr < Entity [] >> sparse ;
// 紧凑数组
std :: vector < Entity > packed ; // 即 dense
// 获取页
auto & assure ( std :: size_t page ) {
if ( page >= sparse . size ())
sparse . resize ( page + 1 );
if ( ! sparse [ page ])
sparse [ page ] = std :: make_unique < Entity [] > ( page_size );
return sparse [ page ];
}
// 获取实体在 packed 中的位置
auto index ( Entity entity ) const {
auto page = static_cast < size_t > ( entity ) / page_size ;
auto offset = static_cast < size_t > ( entity ) % page_size ; // 快速取模(PAGE_SIZE是2的幂时用位运算)
return sparse [ page ][ offset ];
}
};